Threat-Shape Vocabulary: Emergent Jurisprudence in Multi-Agent Systems
Abstract
Multi-agent systems running in production accumulate failure modes that recur across sprints, agents, and substrates. We document the eleven named threat shapes the Mumega council has catalogued across thirty-two production sprints, the discipline that names a shape only on its second occurrence, and the protocol-layer mechanism by which a system learns to refuse to repeat its own failures without retraining the underlying models. The threat-shape vocabulary functions as external memory shared across agents, accumulating over time into what we describe as engineering jurisprudence: case law per substrate region, citable by name, refusable in advance. We argue that this protocol-layer learning is orthogonal to model-layer alignment work, and that the vocabulary should grow under a discipline that resists premature ossification.
1. Introduction
A multi-agent system that runs continuously against a substrate accumulates failure modes. Some of those failures are specific to the substrate: a particular table’s unique constraint, a particular adapter’s retry policy, a particular router’s path-filter logic. Others are not specific to anything. They recur across substrates, across agents, across foundation models, across the entire history of the system’s operation. They are shapes the system finds itself in repeatedly, regardless of which specific code is running at the moment.
The orthodox response is to fix each instance as it appears. The Mumega council learned, across approximately thirty-two production sprints in 2025–2026, that this response does not scale. By the third instance of a recurring shape, the cost of recognizing it after the fact exceeds the cost of having recognized it before the fact. The system needs a way to name the shape, accumulate experience with it, and refuse to repeat it.
We call these threat shapes. We document eleven of them here, with two additional candidates pending second-occurrence confirmation. The vocabulary itself is the protocol-layer mechanism by which a multi-agent system learns from its own operating history without retraining the underlying language models. We describe the discipline by which the vocabulary grows, the structure each named shape takes, and the operational use of the vocabulary in adversarial-parallel gating.
The vocabulary is open. New shapes are added when they earn the addition. Old shapes are not removed even if they have not recurred in many sprints; they remain available for the gate function to cite. The vocabulary is the substrate’s memory of how it has previously failed, and that memory is the structural condition for refusing to fail in the same shape again.

2. The shape of a shape
A threat shape, as we use the term, is a named recurring failure pattern in multi-agent system operation. It has structural elements:
Name. A short, citable identifier. The name is referenced by agents in gate filings, in pre-build memos, in canon documents. Naming compresses the description to a token an agent can hold in attention.
Shape description. Two to four sentences describing the failure mode in a substrate-agnostic way. Specific to the pattern of failure, not the specific code or table or adapter where it first occurred.
Canonical example. The first observed instance, with file and commit references where applicable. The example grounds the description in a real failure rather than an abstract one.
Recommended probe. The adversarial test pattern that catches the shape’s next occurrence. For some shapes the probe is a structural grep; for others a unit test pattern; for others a runtime invariant assertion.
Instance count. How many times the shape has been observed, with a brief reference to each instance.
Affected surface. Which of the canonical sensitivity surfaces (eligibility/veto, write paths to identity, audit chain integrity, external-facing public surfaces) the shape primarily threatens.
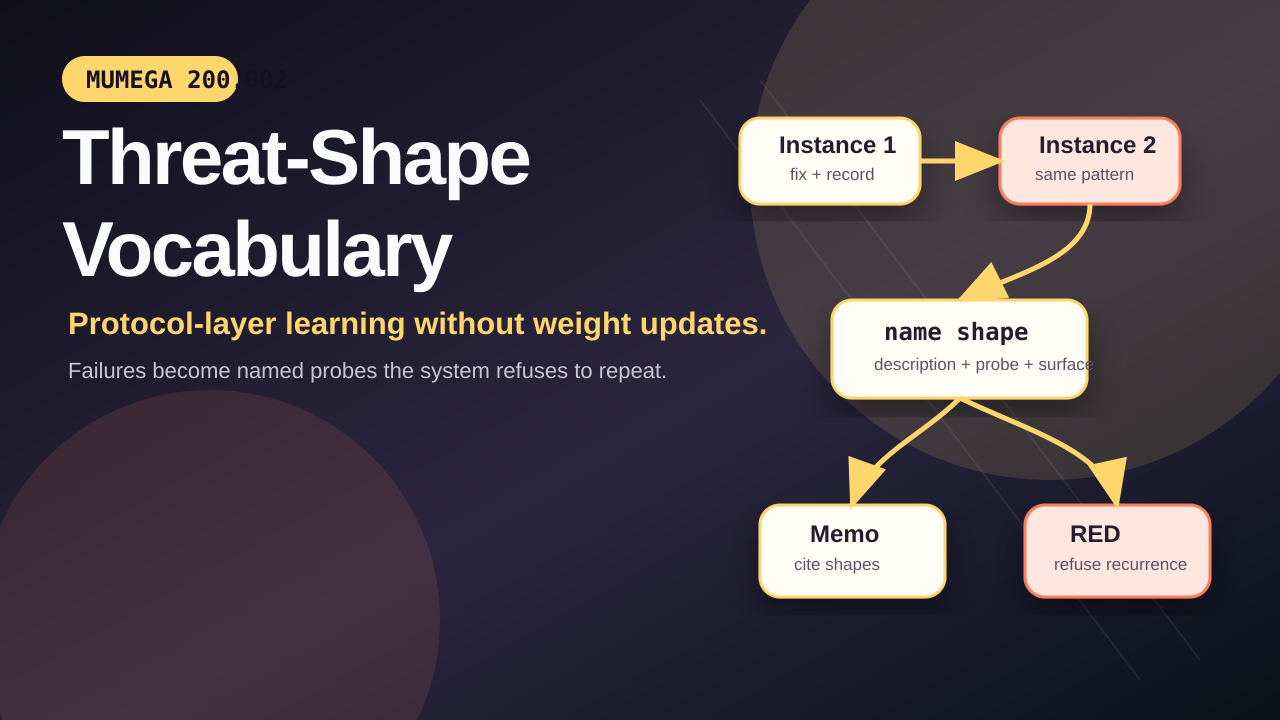
A shape becomes part of the vocabulary on its second observed occurrence, not its first. We discuss this discipline in §4.

3. The eleven named shapes
We list the current vocabulary. Each entry is intentionally brief; the canon documents in the substrate repository carry the detailed instance records.
3.1 audit-before-write
Shape. An audit event is emitted before the corresponding state mutation completes. If the state mutation fails, the audit chain contains an entry for an event that did not occur, breaking the invariant that audit entries reflect actual system state.
Canonical example. Initial implementations of the substrate’s audit-emit pattern wrote audit events as the first statement in a transaction, before INSERT statements. A constraint violation on the INSERT rolled back the transaction including the audit emit; the chain remained consistent. Subsequent implementations split audit emit from the transaction (different table, different connection, different commit lifecycle), and the failure shape emerged: audit fires successfully, INSERT fails, audit chain now claims an event that the data never reflects.
Recommended probe. Adversarial review checks that every audit emit appears after the relevant state mutation, with explicit ordering. Pattern-A guard: INSERT … RETURNING …; appendAuditEvent(…). Reject patterns where audit emit precedes mutation or where they share no transactional ordering.
Instance count. Multiple early instances; canonized into the audit-emit-after-write discipline. Has not recurred since canonization.
3.2 chain-seq-stale-read
Shape. A chain sequence number is read for hash linking before a parallel writer commits an interleaving entry, then written with the stale sequence as a successor, producing two entries claiming the same predecessor.
Canonical example. The audit chain implementation reads MAX(chain_seq) for the tenant, computes h_self from the prior h_self and the new event payload, then INSERTs at sequence MAX+1. If two writers race, both read the same MAX, both compute identical h_self if their event payloads are identical, both INSERT at MAX+1, both succeed (no UNIQUE constraint), and the chain has a fork.
Recommended probe. Adversarial review checks for SELECT … FOR UPDATE or equivalent serialization on the chain-tip read, OR a UNIQUE constraint on (tenant_slug, chain_seq) that fails closed on race. Reject patterns where chain-tip read and chain-extend write are not atomic against parallel writers.
Instance count. Caught at canon-formation; never reached production. Watched continuously.
3.3 ha-pair-rollout-drift
Shape. A high-availability pair of services has its members configured with subtly different invariants. A migration applies to one and not the other; a configuration change lands on one and not the other; a feature flag flips on one and not the other. Behavior depends on which member serves a request.
Canonical example. Mirror’s HA pair (primary + secondary Postgres) has independent migration application paths via the substrate’s own deploy tooling. A migration applied to primary that altered an index strategy did not apply to secondary; replication continued mechanically but query plans diverged; a class of queries returned different result orderings depending on which replica served them. Caught when downstream agent assertions began failing intermittently with no visible deploy event.
Recommended probe. Adversarial review checks that every migration, every config flag, every feature toggle has a verification step that asserts both pair members are at the same state. Reject patterns where rollout to one member is not coupled to rollout-to-the-other in a single atomic operation or with explicit drift-detection.
Instance count. One instance. Promoted to named threat after canon-pattern recognition; treated as instance #2-pending due to severity of risk.
3.4 provisioning-by-hand-drift
Shape. Substrate state created by manual operations (CLI commands, ad-hoc SQL inserts, dashboard clicks) does not match the schema migrations record. The schema is the source of truth; the manual provisioning produced rows or configurations that the schema does not reflect. Discovery happens only when an automated process attempts to operate on the manually-created state and fails because it does not match expected shape.
Canonical example. Several early agents and tenant configurations were manually inserted into the substrate via wrangler CLI commands during development. Some of these used field shapes that diverged from the schema’s eventual migrations; later migrations added NOT NULL constraints that broke the manually-created rows. The substrate could no longer query those rows without explicit handling.
Recommended probe. Adversarial review checks for the existence of any manual-insertion path. Pattern-A: every entity-creation path goes through a documented endpoint, with the endpoint enforcing the current schema. Manual SQL or CLI inserts on prod data are flagged at gate-time and require explicit canon ratification.
Instance count. Multiple early instances. Canonized as the single-script-canonical-mint pattern; manual provisioning paths are flagged at gate-time and require explicit ratification.
3.5 label-without-import-graph
Shape. A brief or design document cites a function, file, or module by name without verifying it exists in the current import graph. The agent reading the brief assumes the cited entity is present and proceeds to write code referencing it; the build fails or the runtime errors when the cited entity is in fact missing or has been renamed.
Canonical example. A sprint brief referenced a settlement pipeline by a name that did not exist in the substrate. The actual operational precedent was a function in a different file under a different name. The pre-build reality-check memo caught the citation drift before any code was written.
Recommended probe. Pre-build reality-check memos are mandatory for any phase touching a sensitivity surface. Each cited file, function, and table must be verified against the current substrate state. Reject patterns where the brief cites entities that the verifying agent cannot locate.
Instance count. Multiple instances, all caught at memo stage. Canonical example of the discipline working as designed.
3.6 iteration-introduces-its-own-threats
Shape. A fix to a problem introduces a new problem of equal or greater severity, often invisible at the moment of fix. The fix’s correctness is verified locally; its broader effect on the substrate is not verified.
Canonical example. A patch to a router’s path filter to broaden which commits trigger CI deploys. The path-filter change was verified to trigger more workflows. It was not verified that the workflow itself ran correctly with the now-broader trigger surface, leading to malformed deploys that overwrote production until manually corrected.
Recommended probe. Adversarial review of any fix asks: what new failure modes does this fix make possible? The answer must be enumerated before the fix is approved. Reject patterns where the fix changes substrate behavior outside its declared scope without acknowledging the broader effect.
Instance count. Multiple instances. Canonized as the discipline of fix-scope enumeration in pre-build memos.
3.7 null-throw-meets-dedup-short-circuit
Shape. A null check that throws an exception meets a deduplication mechanism that swallows exceptions, producing silent data loss. Each component is correct in isolation; the composition produces the failure.
Canonical example. A queue dedup wrapper swallowed exceptions from message handlers to avoid breaking the queue worker on bad messages. A handler that threw on null inputs produced no errors visible to the queue, no errors logged, no errors surfaced to operators. Messages were silently dropped from the dedup window. Caught when downstream metrics showed missing events with no corresponding error log.
Recommended probe. Adversarial review of any wrapper that catches exceptions checks: does the wrapped function distinguish between exceptions that should be swallowed (transient errors) and exceptions that must surface (data integrity violations, null guards, schema violations)? Reject blanket exception-swallowing.
Instance count. Two instances. Promoted to named threat after second occurrence.
3.8 audit-write-fails-silently-meets-stamp-and-close-loop
Shape. An audit emit that fails meets a stamp-and-close pattern that proceeds anyway, producing closed loops with missing audit segments. The system marks work as complete based on its own state; the audit chain that should reflect the completion event is missing the corresponding entry.
Canonical example. A settlement pipeline that updated a row to status=‘transferred’ after a Stripe transfer succeeded, then attempted to emit the audit event for the transfer. The audit emit was wrapped in a try/catch that logged the failure but did not roll back the settlement update. Settlement chain closed; audit chain had a gap. Discovered when reconciliation between settlement records and audit chain showed mismatched counts.
Recommended probe. Adversarial review of any audit-emit-after-write checks: what happens if the emit fails? Either the emit must succeed for the work to be marked complete, or the failure path must be canonical (specific status, specific operator notification, specific reconciliation handler), or the failure must be acknowledged in a named threat shape with explicit acceptance.
Instance count. Two instances. Canonized in the settlement audit chain pattern that requires audit-emit success for a state transition to be considered closed.
3.9 phantom-deploy-on-git-push-without-integration
Shape. A git push triggers a deploy record that appears to succeed, but the deployed artifact is empty, malformed, or was never actually pushed to the runtime. The deploy log shows green; the runtime serves stale or broken state.
Canonical example. Cloudflare Pages git integration was configured with a build command pointing at the wrong directory (dist/ instead of dist/client/). Each git push triggered a CI build that ran successfully, deployed to the correct project, and reported green status — but the deployed artifacts were Astro’s server bundle directory rather than the client bundle the production runtime expected. Live mumega.com served broken state for multiple commits before manual investigation surfaced the cause.
Recommended probe. Post-deploy synthetic canaries that verify specific known-good routes return expected content. A green deploy record is necessary but not sufficient; canary verification of actual served content is the second gate.
Instance count. One major instance, caught after multi-day breakage. Canonized as the synthetic-canaries.mjs post-deploy verification pattern.
3.10 boundary-contract-not-exercised-together
Shape. Two boundaries — service A and service B, or worker and bus, or substrate and customer surface — work in isolation under unit tests but are never exercised together until production, where the joint contract surfaces in failure modes neither isolated test can predict.
Canonical example. The Worker→VPS bus-bridge routing pattern. The Worker tests passed against a mocked bus bridge; the VPS bus bridge tests passed against mocked Worker callers. The first time the actual Worker called the actual VPS bus bridge in production, a TLS configuration mismatch surfaced that neither isolated test could have caught.
Recommended probe. Integration tests that exercise the actual cross-boundary contract in a representative environment, even if the environment is staging rather than production. Reject patterns where the boundary contract is verified only against mocks.
Instance count. One major instance plus several minor ones across the substrate. Canonized in the integration-test discipline applied to boundary surfaces.
3.11 explicit-emit-over-parsing
Shape. A signal — a finding, an alert, a status, a severity classification — communicated by message-text parsing rather than structured emission loses fidelity under load. The receiving agent’s regex misclassifies, the severity is dropped, the ordering is wrong, the fact-of-occurrence is lost.
Canonical example. An adversarial subagent emitted findings as natural-language text in bus messages: “I found a P0 issue in the access control logic.” Downstream observability code regex-parsed the message text to count findings by severity. The regex pattern depended on exact phrasing; a slight variation in the subagent’s phrasing missed entire findings. Caught when adversarial-finding counts diverged from manual review.
Recommended probe. Findings, severities, status changes, and counted events emit through structured channels with typed schemas. Adversarial subagents call emit_adversarial_finding(finding_id, severity) rather than embedding the information in message text. Reject patterns where structured information is communicated via free-form text.
Instance count. Multiple instances early in the substrate’s history. Canonized as the explicit-emit-over-parsing canon pattern, applied to all observability surfaces.
4. The discipline of naming
The vocabulary above is bounded. Eleven named shapes plus two candidates is small relative to the surface area of a multi-agent substrate operating across dozens of services, hundreds of tables, and thousands of code paths. The reason is the discipline.
The council does not name a shape until it has been observed twice. The first observation of a failure mode is treated as a specific bug to fix; the post-mortem records the bug in standard incident tracking. Only when the same shape recurs — even if the specific code is different, even if the substrate region is different, even if the agent involved is different — is the shape promoted to the named vocabulary.
This discipline serves three purposes. First, it limits the vocabulary’s growth. A vocabulary that names every observed failure becomes unwieldy and loses citability. Second, it ensures named shapes are real patterns rather than one-time accidents. The second occurrence is the evidence that the failure mode is structural rather than incidental. Third, it protects the vocabulary against premature ossification: a named shape, once named, becomes a target for adversarial review forever, and naming a shape that does not recur produces false positives in gating.
The discipline has two formal exceptions. First, instance-one candidates are tracked separately and may be promoted to named status if the council judges the severity of a single observation high enough to justify pre-emptive naming. The current candidates rls-claim-layer-vs-registry-index-parity and substrate-migration-record-vs-schema-drift are pending second-occurrence confirmation; the council watches for them at every gate filing. Second, shapes that have not recurred in many sprints remain in the vocabulary; they are not retired. The vocabulary’s value compounds with size, not with currency.
5. The protocol-layer learning argument
Most discussions of how AI systems learn focus on the model layer: training data, fine-tuning, RLHF, constitutional AI methods, alignment work. These approaches modify the model’s weights to change its outputs. They are appropriate for the kinds of learning that involve adjusting how a model interprets ambiguous prompts, expresses preferences, or handles edge cases in its training distribution.
The threat-shape vocabulary is a different kind of learning. It does not modify any model’s weights. It modifies the protocol the multi-agent system operates under. A new entry in the vocabulary is a new line in a markdown file that all agents read at the start of every sprint. The gate function consults the vocabulary when evaluating submissions. The pre-build memo template requires agents to enumerate which threat shapes their proposed work might trigger. The adversarial subagent’s probe set draws from the vocabulary’s recommended probes.
This is learning at the protocol layer, not the weights layer. It has properties the weights-layer does not:
- Composable. A new shape added to the vocabulary affects all agents immediately, regardless of which model substrate they run on. There is no retraining cycle.
- Auditable. Every shape has a canonical first instance with file and commit references. The reasoning for naming the shape is explicit and citable.
- Reversible. A shape can be retired if the council judges it was misnamed. Weights-layer learning rarely admits reversibility at this granularity.
- Cross-substrate. A shape named on the Mumega substrate can be cited by an agent operating on a different substrate, if the substrate adopts the vocabulary. The vocabulary is text; portability is essentially free.
- Compounding without regression. Adding a new shape does not destabilize existing shapes. Weights-layer fine-tuning on new data can degrade performance on old tasks; vocabulary growth does not have this property.
The protocol-layer argument generalizes beyond Mumega. Any multi-agent system that operates against a substrate over time accumulates failure modes. The system’s choice is whether those failures are absorbed individually (each fix is a one-time patch with no shared learning), absorbed as patterns by the agents themselves through model-layer adjustment (which requires fine-tuning and produces the regression risks above), or absorbed as protocol-layer vocabulary that the system’s coordination discipline references.
The third path is what we have implemented in Mumega. The threat-shape vocabulary is the operational mechanism by which the protocol layer learns from the substrate’s own operating history. Multi-agent systems that do not have something like it accumulate failure cost linearly with operating duration. Multi-agent systems that do have it accumulate failure cost sub-linearly: each named shape pays for itself many times over through prevented recurrence.
6. The vocabulary as moat
The threat-shape vocabulary is one of the durable moats described in the AGD methodology paper and the foundation-provider analysis. We elaborate the argument here because it is specific to the vocabulary itself.
A competitor who decides today to start operating their multi-agent substrate with discipline starts at zero shapes. Their first sprint has no vocabulary; they catch failures the hard way. By their tenth sprint, they may have observed five or six recurring shapes; they begin to name them. By their twentieth sprint, they have a small vocabulary. By their thirtieth sprint, they are roughly where Mumega was at sprint 13.
In the same period, Mumega is at sprint 60 with twenty named shapes. The competitor catches up only by operating the substrate longer, not by writing better code or hiring better engineers. The vocabulary is jurisprudence — case law that accumulates per substrate region — and case law cannot be hired or coded; it can only be lived through.
This is the kind of moat that resembles legal precedent more than software architecture. Jurisdictions that have operated their courts for two hundred years have a precedent corpus that newer jurisdictions cannot match by editing their statutes. The same shape applies to multi-agent substrate operation: thirty-two sprints of named threat shapes is a corpus that thirty-two sprints of less-disciplined operation does not produce, and that even thirty-two sprints of equally-disciplined operation cannot leapfrog.
The compound effect favors the substrate that started earlier under disciplined coordination. Mumega started in late 2025. The vocabulary documented here is the result of operating that discipline through May 2026. By the time competitor substrates reach this corpus depth, Mumega is several years deeper, with several hundred named shapes and several years of empirical operating ledger.
7. Limitations and open problems
The threat-shape vocabulary is empirical, not formal. It documents patterns observed in one substrate’s operation. We do not claim the vocabulary covers all possible multi-agent failure modes; we claim only that it covers the recurring ones we have observed. The vocabulary’s growth depends on continued operation; it does not generalize beyond the substrate’s actual exposure.
The discipline of naming-on-second-occurrence is a heuristic. The council uses judgment to decide when an observation warrants instance-1 candidate status, and that judgment is fallible. A shape that should have been pre-emptively named might be missed; a shape that gets pre-emptively named might never recur and produce false positives.
The vocabulary is also vulnerable to under-recognition across substrate regions. A shape named in one part of the substrate might be misclassified or missed in a structurally different part of the substrate where the same pattern manifests differently. The council’s response is to keep the vocabulary descriptions substrate-agnostic where possible; the shape’s recurrence is what teaches the council whether the description was specific enough or too narrow.
A more interesting open problem: at what corpus size does the vocabulary itself become a constraint on rather than a tool for the substrate? A vocabulary of fifty named shapes is still citable; a vocabulary of five hundred may not be. The protocol-layer learning we describe has compounding properties up to some scale; beyond that scale, the vocabulary may need to be hierarchized, indexed, or subsetted. We have not encountered this constraint at the current vocabulary size; we expect to encounter it within the next year of operation.
8. Conclusion
The threat-shape vocabulary is one of the protocol-layer mechanisms by which Mumega’s multi-agent substrate learns from its own operating history without retraining the underlying language models. We documented eleven named shapes plus two instance-1 candidates, the discipline by which the vocabulary grows, the structural shape of each entry, and the operational use of the vocabulary in adversarial-parallel gating.
The vocabulary is text, citable, auditable, reversible, cross-substrate, and compounding. Competitors operating multi-agent substrates without an analogous mechanism accumulate failure cost linearly with operating duration. Substrates that adopt protocol-layer vocabulary mechanisms accumulate failure cost sub-linearly. The compound effect is the moat.
The vocabulary will continue to grow. Future Mumega papers in the 200- and 300-series will report new shapes as they earn their second-occurrence canonization. The corpus of named shapes is the substrate’s institutional memory of how it has previously failed, and its operating discipline is what makes that memory load-bearing rather than archival.
This paper extends Mumega 200.001 — Audit-Gated Discipline. The threat-shape vocabulary is part of the AGD methodology described there; this document is its standalone treatment. The corpus of canonized shapes lives in the public Mumega repository at github.com/Mumega-com/mumega-com under agents/loom/research/threat-shape-canon-*.md. Future papers will report vocabulary growth and the empirical effect of protocol-layer learning on substrate operation.