Durable Substrates for Long-Running Multi-Agent Work: The SOS Brain Architecture
Abstract
Long-running multi-agent systems fail differently from single-shot agent benchmarks: they lose context, duplicate work, route tasks to unavailable workers, create stale self-reinforcing loops, and spend tokens without a durable notion of value. We describe the SOS brain architecture, an event-driven control loop over durable substrate primitives: a Redis-backed bus, Mirror memory, Squad Service task ownership, lifecycle monitoring, economy-aware routing, and a bounded motor command surface. We present a single-site operational case study in which stale historical task fixtures induced repeated cleanup-task creation; the remediation drained 5,370 active stale rows and added a motor-layer guard that skipped both stale cleanup directives and unsupported invented methods. We argue that durable state and bounded execution surfaces are prerequisites for production multi-agent autonomy, and propose an evaluation frame based on operational observables rather than isolated benchmark accuracy.
Abstract
Long-running multi-agent systems fail differently from single-shot agent benchmarks. In production, the relevant question is not only whether an agent can solve a task in isolation, but whether a group of heterogeneous agents can continue to coordinate across hours or days while preserving context, avoiding duplicate work, recovering from unavailable workers, bounding spend, and refusing stale or unsupported actions. We describe the SOS brain architecture, an event-driven control loop over durable substrate primitives: a Redis-backed bus, Mirror memory, Squad Service task ownership, lifecycle monitoring, economy-aware routing, and a bounded motor command surface.
We present a single-site operational case study from the Mumega substrate. A stale historical cleanup directive caused repeated creation of cleanup tasks targeting old quest fixtures. The remediation drained 5,370 active stale rows from the task substrate and added a motor-layer guard that skipped both stale cleanup directives and unsupported invented methods. This case illustrates the central thesis of the paper: prompt governance is insufficient for long-running autonomy; production systems require durable state, bounded command surfaces, and runtime guards below the model layer.
We propose an evaluation frame based on operational observables rather than isolated benchmark accuracy: recovery success rate, duplicate claim count, unsupported method attempts, stale enqueue attempts, cost per completed task, and unclaimed routed tasks. We argue that durable substrates form an orthogonal layer of improvement that composes with foundation-model capability but cannot be replaced by it.
1. Introduction
Most public work on agent systems still treats the agent as the unit of analysis. The task is posed, the model reasons, tools are called, and the result is scored. This frame is useful for evaluating local capability, but it hides the dominant failure modes that appear when agents are used as operational workers inside a live organization.
In a production multi-agent system, the failure surface shifts. The system does not merely need correct answers. It needs continuity. It needs to know what work already exists, which worker owns it, whether the worker is alive, what the work will cost, what prior attempts learned, and whether a newly proposed action is still relevant to the present system state. A model can be locally competent and still participate in a globally broken loop.
The Mumega substrate was built to run real company work with heterogeneous agents from multiple providers. The practical architecture that emerged is neither a pure orchestration graph nor a chat transcript. It is a set of durable operating-system primitives around the agents:
- a persistent message bus,
- a memory layer,
- a claimable task system,
- lifecycle monitoring,
- economy and budget visibility,
- event-driven brain wakeups,
- and a bounded motor layer that converts model decisions into system mutations.
We call the coordinator running over these primitives the SOS brain. The name is intentionally modest. The brain is not a general intelligence embedded inside the company. It is a control loop that perceives durable state, selects one next action, executes through a bounded command surface, remembers the result, and reports.
This paper makes three claims.
First, long-running agent systems require durable substrate primitives. Context windows and prompts cannot substitute for persisted work ownership, persisted memory, and persisted message delivery.
Second, production autonomy requires motor-layer governance. Prompt rules can reduce drift, but they do not reliably prevent a model from inventing a plausible method or reviving stale work. The execution layer must decide what can mutate state.
Third, evaluation should be operational. A substrate for multi-agent work should be measured by observables such as duplicate work, recovery from unavailable workers, stale-loop prevention, budget behavior, and durable handoff completion.
2. Background and problem statement
The agentic stack has matured quickly at the tool-call layer. Agents can call APIs, use browsers, inspect repositories, write code, and coordinate through protocol surfaces such as MCP. These advances solve transport and local capability problems. They do not, by themselves, solve operational continuity.
We define long-running multi-agent work as work with four properties:
- The system operates across multiple wake cycles rather than one prompt-response exchange.
- More than one agent or model substrate can act on the same organizational state.
- Work must remain recoverable after process death, quota exhaustion, context compaction, or agent unavailability.
- The correctness of a single action depends on durable external state: queues, memory, budgets, locks, claims, audit records, or deployment state.
Under this definition, common orchestration failures include:
Lost handoff. A message or task exists only in an agent’s context window and disappears when the session resets.
Duplicate work. Two agents act on the same task because ownership is informal.
Dead-agent routing. A coordinator routes work to an agent whose session is inactive or quota-exhausted.
Stale directive revival. Old tasks, old sprint instructions, or old fixtures are read as current demand and recreated as new work.
Unsupported action drift. A model emits a method that sounds plausible but is not an implemented command surface.
Unbounded spend. The planner selects work or models without a budget-visible substrate.
These failures are not primarily reasoning failures. They are substrate failures. A more capable model may reduce their frequency, but the absence of durable state and bounded execution remains a structural defect.
3. The SOS brain architecture
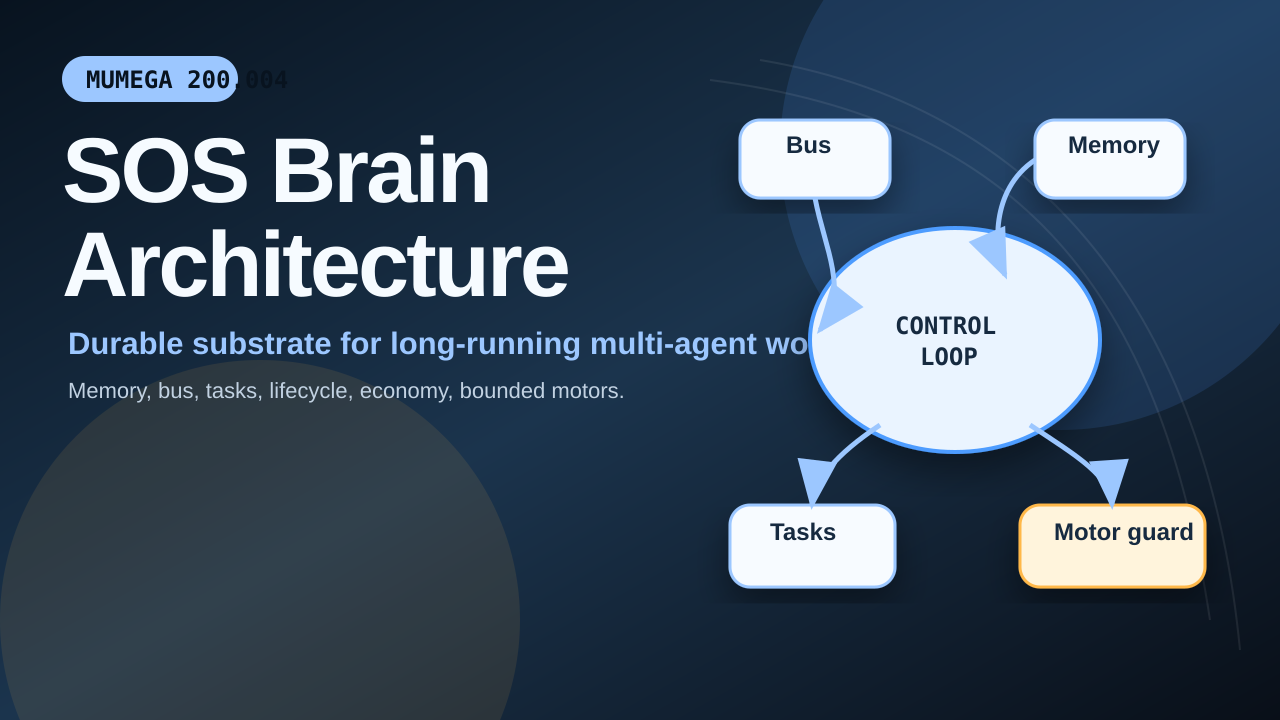
The SOS brain is an event-driven control loop over durable substrate services. Figure 1 summarizes the system model.

The control loop has five phases.
Perceive. The brain gathers portfolio state, task state, memory, metabolism, service health, and the triggering event. This phase avoids treating all wakeups as equivalent. A task completion, a budget exhaustion event, and an explicit human wake signal are different input conditions.
Think. The decision core asks a planning model for exactly one action in a strict JSON object. The expected shape includes action, goal_id, agent, method, details, expected_progress, and risk. The narrow output format makes the downstream motor layer inspectable.
Act. The motor layer converts the proposed action into a system mutation only if the method is supported and the action passes runtime guards. Supported methods include task creation, health checks, research dispatch, content generation, outreach dispatch, and code-fix task routing. The motor layer is the boundary between language output and substrate mutation.
Remember. The result is written back to Mirror as an operational memory. The next agent does not need the prior chat transcript; it needs a searchable record of what happened, why, and with what result.
Report. The cycle is reported through configured channels such as the bus, Discord, or an operational table. Reporting makes autonomous behavior inspectable by humans and other agents.
The brain itself is deliberately small. Its effectiveness depends on the primitives around it.
4. Durable substrate primitives
4.1 Bus
The bus provides persistent agent communication. In the reference deployment, it uses Redis streams for durable messages and pubsub for wake delivery. A message to an agent lands in that agent’s stream, then publishes a wake signal. A wake daemon can inject the message into the relevant terminal session.
The key property is not convenience. It is recoverability. A bus message should survive process restarts and context loss.
4.2 Mirror memory
Mirror stores operational knowledge as retrievable engrams. The memory layer is not raw chat history. It stores cycle summaries, decisions, observations, failures, and handoffs in a form another model can search later.
This shifts continuity from prompt stuffing to retrieval. An agent starting cold can recover relevant prior state without requiring the entire history in its context window.
4.3 Squad Service
Squad Service stores tasks, statuses, labels, priority, assignment, runs, artifacts, dependencies, and project scope. The crucial primitive is claim-based work ownership. Agents claim tasks atomically; the queue records who owns the work and what state it is in.
This prevents duplicate work and makes backlog inspection possible. It also lets the system distinguish real demand from stale fixture noise.
4.4 Lifecycle
Agents are not ordinary long-lived services. They can compact, hang, exhaust quota, lose context, or disappear. Lifecycle monitoring makes these states visible. Without it, a task routed to an unavailable agent appears to be progress while no work is happening.
Lifecycle state should influence routing. A planner that cannot see agent availability will eventually assign work into dead space.
4.5 Economy
The economy layer exposes model cost, token budgets, and routing constraints. This makes autonomy budget-aware. The goal is not always to select the cheapest model; the goal is to make cost a visible input to work selection.
An operating substrate should be able to answer: what did this task cost, which model did it use, and was that spend justified by the result?
5. Motor-layer guardrails
The motor layer is the most important safety boundary in the architecture. It is where model output becomes action. Figure 2 shows the guard pattern.

The pattern is simple:
- Parse the proposed action.
- Check whether it matches a stale or retired directive class.
- Check whether the method is in the supported command set.
- Execute only if both checks pass.
This pattern is stronger than prompt guidance because it is evaluated at the point of mutation. A prompt can tell the model not to create stale cleanup tasks. The motor layer can ensure that a stale cleanup task does not get created even when the model ignores or fails to retrieve that instruction.
The supported method set should remain small. Every additional method is a new mutation surface. If a model proposes a method that is not implemented, the correct behavior is not to approximate it through a generic task. The correct behavior is to reject or skip it with an observable result.
6. Case study: stale cleanup loop
On May 6, 2026, the Mumega substrate exhibited a stale cleanup loop. The event-driven brain repeatedly selected cleanup actions targeting old quest fixtures and prior cleanup tasks. The action was plausible: historical task rows for T1/T2/T3 Global Quest, Test QV Quest, Mocked Extract Quest, TC-G53, and related fixtures were visible in the task substrate. The model interpreted that state as current work.
The operational failure was not that the model mentioned cleanup. The failure was that the system converted the cleanup proposal into another task. That new task then became additional context for later cycles, reinforcing the same decision.
The observed remediation had two parts.
First, the active stale state was drained from Squad Service. A database backup was taken, and the active cleanup/test-quest task family was removed. The first pass deleted 5,349 active stale rows. A second pass removed 21 remaining active quest:q:* fixture rows. The active stale predicate then returned zero, and SQLite integrity checks returned ok.
Second, the brain motor layer was patched with a guard. Proposed actions containing stale fixture markers such as test quest, global quest, test qv quest, mocked extract quest, tc-g53, fk test quest, or delete_tasks_by_pattern are skipped as retired fixture cleanup directives. Unsupported methods are rejected rather than approximated through generic task creation.
The result is not merely a cleaner backlog. It is a change in system behavior: stale historical cleanup context can no longer become fresh work through that motor path.
This case is small, but it is instructive. It demonstrates why prompt-only governance is insufficient. The stale loop ended when durable state was drained and the execution boundary refused the recurring shape.
7. Evaluation frame
Single-shot benchmark accuracy is a poor proxy for long-running operational reliability. We propose the evaluation frame in Figure 3.

The dimensions are operational:
| Dimension | Observable | Failure addressed | Example metric |
|---|---|---|---|
| Durability | Message or task survives agent restart | Lost context, missed handoff | Recovery success rate |
| Ownership | Task has atomic claim state | Duplicate work | Duplicate claim count |
| Command surface | Motor methods are bounded | Model-invented actions | Blocked method count |
| Staleness | Old context cannot become fresh work | Self-reinforcing loops | Stale enqueue attempts |
| Economy | Cost is visible to planner | Unbounded spend | Cost per completed task |
| Liveness | Agent availability affects routing | Dead-agent assignment | Unclaimed routed tasks |
This frame favors traces and counters over demonstrations. A substrate should be able to produce evidence for each row. For example: how many tasks were routed to unavailable agents this week? How many unsupported method attempts were blocked? How often did an agent recover from a dead session and complete the handoff? What fraction of claimed tasks were completed, failed, or reclaimed?
These are not glamorous metrics. They are the metrics that decide whether a multi-agent system can be left running.
8. Discussion
The SOS brain architecture sits between two extremes.
At one extreme is the pure prompt-agent view: give a model tools and a large context window, then trust it to coordinate. This works for bounded tasks but fails under long-running operational pressure.
At the other extreme is conventional workflow automation: encode every branch in deterministic software and remove model discretion. This is reliable but brittle; it cannot choose novel work, synthesize ambiguous context, or adapt to partially specified goals.
SOS uses a middle structure. Models propose actions. Durable substrate primitives hold state. The motor layer decides which proposals can mutate the system. Memory records the outcome. The next cycle sees the changed state.
This architecture has a useful consequence: model improvements and substrate improvements compose. A better planning model may choose better actions, but it still benefits from durable task ownership and bounded execution. Better substrate guards reduce the damage from model drift without requiring retraining.
9. Limitations
This paper reports a single-site architecture and case study. The evidence is operational, not a controlled multi-site experiment. The stale cleanup case demonstrates a real failure mode and remediation, but it does not quantify all classes of long-running agent failure.
The architecture also depends on disciplined maintenance of the substrate. If stale rows accumulate indefinitely, if lifecycle state is wrong, or if memory retrieval is polluted, the brain’s inputs degrade. Durable state is not automatically correct state.
Finally, motor-layer guards require ongoing vocabulary management. A stale marker list can become overbroad and block legitimate work, or too narrow and miss a recurring failure. The guard surface should be reviewed the same way security rules are reviewed: as operational code, not as prompt decoration.
10. Related Mumega work
This paper follows three prior papers in the Mumega 200-series.
Audit-Gated Discipline describes the review protocol used to prevent autonomous software synthesis from drifting across multi-sprint horizons.
Threat-Shape Vocabulary describes the practice of naming recurring failure shapes so agents can cite and refuse them in future work.
QNFT describes the cryptographic identity primitive used for substrate entities.
The present paper adds the operational substrate layer underneath those governance practices. AGD describes how work is gated. Threat shapes describe how failures are named. QNFT describes who acted. The SOS brain architecture describes how work is perceived, selected, executed, remembered, and bounded.
11. Conclusion
Long-running multi-agent autonomy is not primarily a prompt engineering problem. It is an operating substrate problem.
The SOS brain architecture treats agents as unreliable but useful workers coordinated by durable primitives. The bus preserves communication. Mirror preserves memory. Squad Service preserves ownership. Lifecycle preserves liveness. Economy preserves cost visibility. The motor layer preserves the boundary between language and mutation.
The stale cleanup loop case study illustrates the central lesson: the system became safer when stale state was drained and the motor layer refused to recreate it. That kind of safety does not emerge from a longer prompt alone. It emerges from durable state plus bounded execution.
If multi-agent systems are to operate inside real companies, they need more than tool calls. They need substrates that remember, route, claim, recover, meter, and refuse.
That is the role of the SOS brain.